- Overview
- Finite-State Machines
- Regular Expressions
- Using Regular Expressions and Finite-State Machines to Define a Scanner
- A compiler recognizes legal programs in some (source) language.
- A finite-state machine recognizes legal strings in some language.
- Nodes are states.
- Edges (arrows) are transitions. Each edge should be labeled with a single character. In this example, we've used a single edge labeled "letter" to stand for 52 edges labeled 'a', 'b', $\ldots$, 'z', 'A', $\ldots$, 'Z'. (Similarly, the label "letter,digit" stands for 62 edges labeled 'a',...'Z','0',...'9'.)
- S is the start state; every FSM has exactly one (a standard convention is to label the start state "S").
- A is a final state. By convention, final states are drawn using a double circle, and non-final states are drawn using single circles. A FSM may have more than one final state.
- The FSM starts in its start state.
- If there is a edge out of the current state whose label matches the current input character, then the FSM moves to the state pointed to by that edge, and "consumes" that character; otherwise, it gets stuck.
- The finite-state machine stops when it gets stuck or when it has consumed all of the input characters.
- The entire string is consumed (the machine did not get stuck), and
- the machine ends in a final state.
xtmp2XyZzyposition27123a?13apples- a sequence of one or more letters and/or digits,
- followed by an at-sign,
- followed by one or more letters,
- followed by zero or more extensions.
- An extension is a dot followed by one or more letters.
- $Q$ is a finite set of states ($\{\mathrm{S,A,B}\}$ in the above example).
- $\Sigma$ (an uppercase sigma) is the alphabet of the machine, a finite set of characters that label the edges ($\{+,-,0,1,...,9\}$ in the above example).
- $q$ is the start state, an element of $Q$ ($\mathrm{S}$ in the above example).
- $F$ is the set of final states, a subset of $Q$ ({B} in the above example).
- $\delta$ is the state transition relation: $Q \times \Sigma \rightarrow Q$ (i.e., it is a function that takes two arguments -- a state in $Q$ and a character in $\Sigma$ -- and returns a state in $Q$).
- Deterministic:
- No state has more than one outgoing edge with the same label.
- Non-Deterministic:
- States may have more than one outgoing edge with same label.
- Edges may be labeled with $\varepsilon$ (epsilon), the empty string. The FSM can take an $\varepsilon$-transition without looking at the current input character.
- Have a variable named state, initialized to S (the start state).
- Repeat:
- read the next character from the input
- use the table to assign a new value to the state variable
- $\mathrm{digit} \; | \; \mathrm{letter} \; \mathrm{letter}$
- $\mathrm{digit} \; | \; \mathrm{letter} \; \mathrm{letter}$*
- $\mathrm{digit} \; | \; \mathrm{letter}$*
- ID + ID
- ID * ID
- ID == ID
- The scanner sometimes needs to look one or more characters
beyond
the last character of the current token, and then needs to "put
back" those characters so that the next time the scanner is called
it will have the correct current character.
For example, when scanning a program written in the simple
assignment-statement language defined above, if the input is
"==", the scanner should return the EQUALS token, not two ASSIGN
tokens. So if the current character is "=", the scanner must
look at the next character to see whether it is another "="
(in which case it will return EQUALS), or is some other character
(in which case it will put that character back and return ASSIGN).
- It is no longer correct to run the FSM program until the machine gets stuck or end-of-input is reached, since in general the input will correspond to many tokens, not just a single token.
- modify the machines so that a state can have an associated action to "put back N characters" and/or to "return token XXX",
- we must combine the finite-state machines for all of the tokens in to a single machine, and
- we must write a program for the "combined" machine.
- The table will include a column for end-of-file as well as for all possible characters (the end-of-file column is needed, for example, so that the scanner works correctly when an identifier is the last token in the input).
- Each table entry may include an action as well as or instead of a new state.
- Instead of repeating "read a character; update the state variable" until the machine gets stuck or the entire input is read, the code will repeat: "read a character; perform the action and/or update the state variable" (eventually, the action will be to return a value, so the scanner code will stop, and will start again in the start state next time it is called).
Scanning
OverviewL
Recall that the job of the scanner is to translate the sequence of characters that is the input to the compiler to a corresponding sequence of tokens. In particular, each time the scanner is called it should find the longest sequence of characters in the input, starting with the current character, that corresponds to a token, and should return that token.
It is possible to write a scanner from scratch, but it is often much easier and less error-prone approach is to use a scanner generator like lex or flex (which produce C or C++ code), or jlex (which produces java code). The input to a scanner generator includes one regular expression for each token (and for each construct that must be recognized and ignored, such as whitespace and comments). Therefore, to use a scanner generator you need to understand regular expressions. To understand how the scanner generator produces code that correctly recognizes the strings defined by the regular expressions, you need to understand finite-state machines (FSMs).
Finite State MachinesLA finite-state machine is similar to a compiler in that:
In both cases, the input (the program or the string) is a sequence of characters.
Here's an example of a finite-state-machine that recognizes Pascal identifiers (sequences of one or more letters or digits, starting with a letter):
In this picture:
A FSM is applied to an input (a sequence of characters). It either accepts or rejects that input. Here's how the FSM works:
An input string is accepted by a FSM if:
The language defined by a FSM is the set of strings accepted by the FSM.
The following strings are in the language of the FSM shown above:
The following strings are not in the language of the FSM shown above:
Write a finite-state machine that accepts e-mail addresses, defined as follows:
Let us consider another example of an FSM:
Example: Integer LiteralsLThe following is a finite-state machine that accepts integer literals with an optional + or - sign:
Formal Definition
An FSM is a 5-tuple: $(Q,\Sigma,\delta,q,F)$
Here's a definition of $\delta$ for the above example, using a state transition table:
| + | - | $\mathrm{digit}$ | |
| $S$ | $A$ | $A$ | $B$ |
| $A$ | $B$ | ||
| $B$ | $B$ |
Deterministic and Non-Deterministic FSMsL
There are two kinds of FSM:
Example
Here is a non-deterministic finite-state machine that recognizes the same language as the second example deterministic FSM above (the language of integer literals with an optional sign):
Sometimes, non-deterministic machines are simpler than deterministic ones, though not in this example.
A string is accepted by a non-deterministic finite-state machine if there exists a sequence of moves starting in the start state, ending in a final state, that consumes the entire string. For example, here's what happens when the above machine is run on the input "+75":
| After scanning | Can be in these states | ||
| (nothing) | $S$ | $A$ | |
| $+$ | $A$ | (stuck) | |
| $+7$ | $B$ | (stuck) | |
| $+75$ | $B$ | (stuck) | |
It is worth noting that there is a theorem that says:
-
For every non-deterministic finite-state machine $M$,
there exists a deterministic machine $M'$ such that $M$ and
$M'$ accept the same language.
How to Implement a FSM
The most straightforward way to program a (deterministic) finite-state machine is to use a table-driven approach. This approach uses a table with one row for each state in the machine, and one column for each possible character. Table[j][k] tells which state to go to from state j on character k. (An empty entry corresponds to the machine getting stuck, which means that the input should be rejected.)
Recall the table for the (deterministic) "integer literal" FSM given above:
| + | - | $\mathrm{digit}$ | |
| $S$ | $A$ | $A$ | $B$ |
| $A$ | $B$ | ||
| $B$ | $B$ |
The table-driven program for a FSM works as follows:
Regular Expressions
Regular expressions provide a compact way to define a language that can be accepted by a finite-state machine. Regular expressions are used in the input to a scanner generator to define each token, and to define things like whitespace and comments that do not correspond to tokens, but must be recognized and ignored.
As an example, recall that a Pascal identifier consists of a letter, followed by zero or more letters or digits. The regular expression for the language of Pascal identifiers is:
-
letter . (letter | digit)*
| | | means "or" |
| . | means "followed by" |
| * | means zero or more instances of |
| ( ) | are used for grouping |
Often, the "followed by" dot is omitted, and just writing two things next to each other means that one follows the other. For example:
-
letter (letter | digit)*
In fact, the operands of a regular expression should be single characters or the special character epsilon, meaning the empty string (just as the labels on the edges of a FSM should be single characters or epsilon). In the above example, "letter" is used as a shorthand for:
-
a | b | c | ... | z | A | ... | Z
To understand a regular expression, it is necessary to know the precedences of the three operators. They can be understood by analogy with the arithmetic operators for addition, multiplication, and exponentiation:
| Regular Expression Operator |
Analogous Arithmetic Operator |
Precedence |
| | | plus | lowest precedence |
| . | times | middle |
| * | exponentiation | highest precedence |
So, for example, the regular expression:
-
$\mathrm{letter}.\mathrm{letter} | \mathrm{digit}\mathrm{^*}$
-
$(\mathrm{letter}.\mathrm{letter}) | (\mathrm{digit}\mathrm{^*})$
Describe (in English) the language defined by each of the following regular expressions:
Example: Integer LiteralsL
Let's re-examine the example of integer literals for regular-expressions:
An integer literal with an optional sign can be defined in English as:
The corresponding regular expression is:
Note that the regular expression for "one or more digits" is:
i.e., "one digit followed by zero or more digits". Since "one or more" is a common pattern, another operator, +, has been defined to mean "one or more". For example, $\mathrm{digit}$+ means "one or more digits", so another way to define integer literals with optional sign is:
The Language Defined by a Regular ExpressionL
Every regular expression defines a language: the set of strings that match the expression. We will not give a formal definition here, instead, we'll give some examples:
| Regular Expression | Corresponding Set of Strings | |
| $\varepsilon$ | $\{$""$\}$ | |
| a | $\{$"a"$\}$ | |
| a.b.c | $\{$"abc"$\}$ | |
| a | b | c | $\{$"a", "b", "c"$\}$ | |
| (a | b | c)* | $\{$"", "a", "b", "c", "aa", "ab", $\ldots$, "bccabb", $\ldots$ $\}$ |
Using Regular Expressions and FSMs to Define a ScannerL
There is a theorem that says that for every regular expression, there is a finite-state machine that defines the same language, and vice versa. This is relevant to scanning because it is usually easy to define the tokens of a language using regular expressions, and then those regular expression can be converted to finite-state machines (which can actually be programmed).
For example, let's consider a very simple language: the language of assignment statements in which the left-hand side is a Pascal identifier (a letter followed by one or more letters or digits), and the right-hand side is one of the following:
| Token | Regular Expression |
| assign | "=" |
| id | letter (letter | digit)* |
| plus | "$+$" |
| times | "$*$" |
| equals | "="."=" |
These regular expressions can be converted into the following finite-state machines:
| assign: | |
| id: | |
| plus: | |
| times: | |
| equals: |
Given a FSM for each token, how do we write a scanner? Recall that the goal of a scanner is to find the longest prefix of the current input that corresponds to a token. This has two consequences:
Furthermore, remember that regular expressions are used both to define tokens and to define things that must be recognized and skipped (like whitespace and comments). In the first case a value (the current token) must be returned when the regular expression is matched, but in the second case the scanner should simply start up again trying to match another regular expression.
With all this in mind, to create a scanner from a set of FSMs, we must:
For example, the FSM that recognizes Pascal identifiers must be
modified as follows:
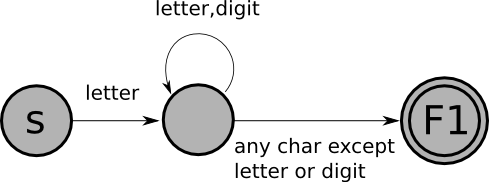
with the following table of actions:
F1: put back 1 char, return ID
And here is the combined FSM for the five tokens (with the actions noted below):
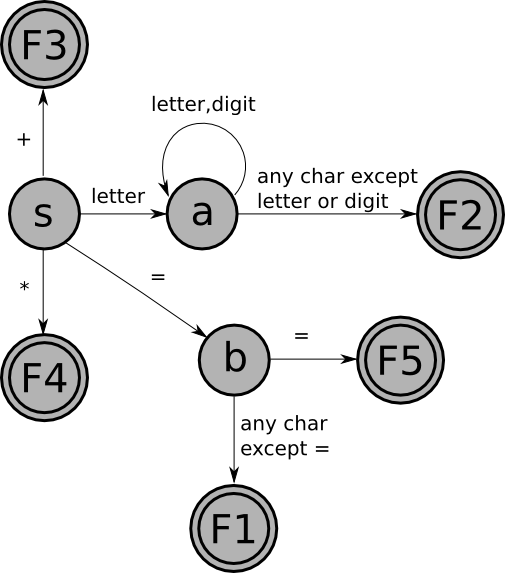
with the following table of actions:
F1: put back 1 char; return assign
F2: put back 1 char; return id
F3: return plus
F4: return times
F5: return equals
We can convert this FSM to code using the table-driven technique described above, with a few small modifications:
| + | * | = | $\mathrm{letter}$ | $\mathrm{digit}$ | EOF | |
| $S$ | return plus | return times | $B$ | $A$ | ||
| $A$ | put back 1 char; return id |
put back 1 char; return id |
put back 1 char; return id |
$A$ | $A$ | return id |
| $B$ |
put back 1 char; return assign |
put back 1 char; return assign |
return equals |
put back 1 char; return assign |
put back 1 char; return assign |
return assign |
Suppose we want to extend the very simple language of assignment statements defined above to allow both integer and double literals to occur on the right-hand sides of the assignments. For example:
would be a legal assignment.
What new tokens would have to be defined? What are the regular expressions, the finite-state machines, and the modified finite-state machines that define them? How would the the "combined" finite-state machine given above have to be augmented?